

Chat With RTX - AI LLM - training local utilizând datele tale
version in English: Chat With RTX – LLM local training using your data
NVIDIA a lansat Chat With RTX, o aplicație demo prin care poți avea propriul chatbot, local, folosind datele tale (documente și video din Youtube).
De ce este important?
- Democratizarea accesului la modele LLM și posibilitatea de a face training fără a scrie cod
- Confidențialitate – datele tale rămân stocate local, nu sunt transmise către un serviciu cloud
Cerințe:
- Windows 11
- NVIDIA GeForce™ RTX 30 or 40 Series GPU or NVIDIA RTX™ Ampere or Ada Generation GPU with at least 8GB of VRAM
- Minim 16GB RAM
- Între 35-50GB spațiu
Am testat Chat With RTX folosind un Surface Laptop Studio 2, i7-13800H, 64GB, RTX4060 8GB.
Trainingul pe un set de aproximativ 3000 de fișiere txt a durat în jur de 10 ore. Nu mă așteptam la cifre impresionante având în vedere platforma mobilă utilizată, dar este totuși o durată acceptabilă.
Următoarea idee a fost să fac training pe tot conținutul de pe blog. În total au fost 244 de fișiere. Un scurt script pentru Wordpress este disponibil aici dump_wp_to_txt.

Chat With RTX foloseste LLM-ul Mistral 7B int4, 7B reprezintă numărul de parametri și în acest caz este de 7.3 miliarde. Chat With RTX poate fi folosit doar cu modelul de bază Mistral 7B sau se poate indica un folder care conține documente și acestea pot fi indexate apoi folosite pentru a “alinia” modelul Mistral 7B.
Procesul de “aliniere” al unui LLM presupune furnizarea unor date suplimentare cu scopul de a-l “specializa”. Putem spune că modelul de bază reprezintă școala generală iar “aliniamentul” reprezintă informația specifică cum ar fi “matematica” sau “chimia”.
În cazul de față am furnizat LLM-ului folderul cu toate articolele de pe blog in format txt. Fișierele vor fi indexate la prima utilizare, aplicația va începe trainingul și un nou folder va fi creat “nume-folder_vector_embedding” care va conține fiăiere JSON folosite de model:

Începerea procesului de training a ocupat toată memoria VRAM a plăcii RTX4060 (8GB) și aproximativ 10 GB RAM:


La finalizarea procesului vom putea folosi Chat With RTX și o pagină web (locală) se va deschide în browser.
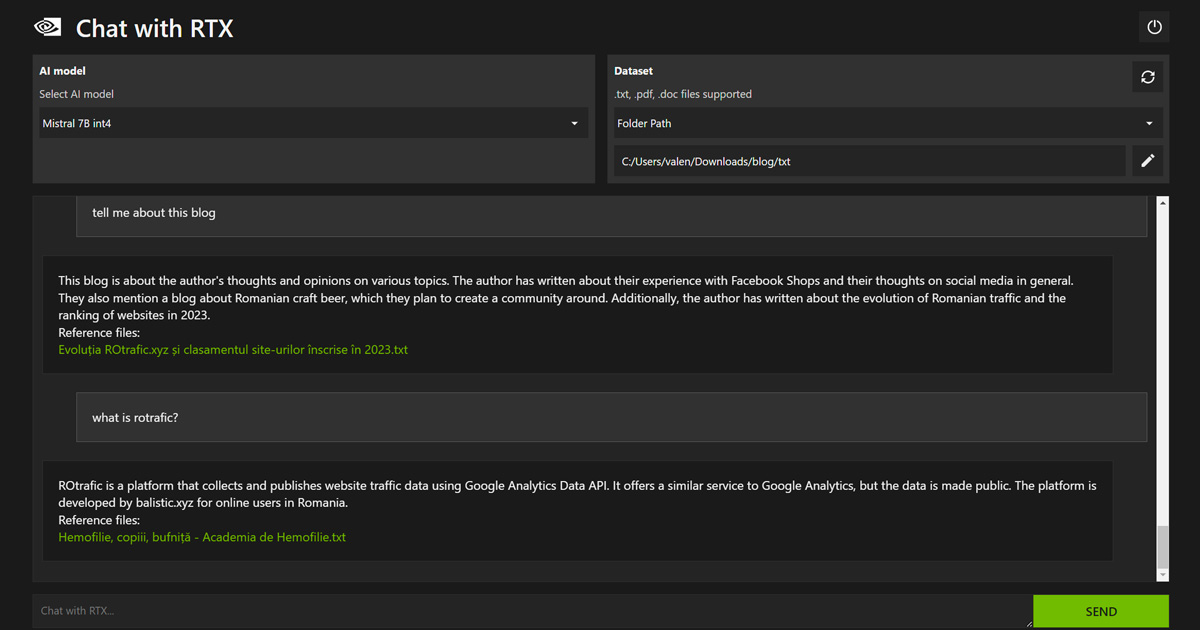
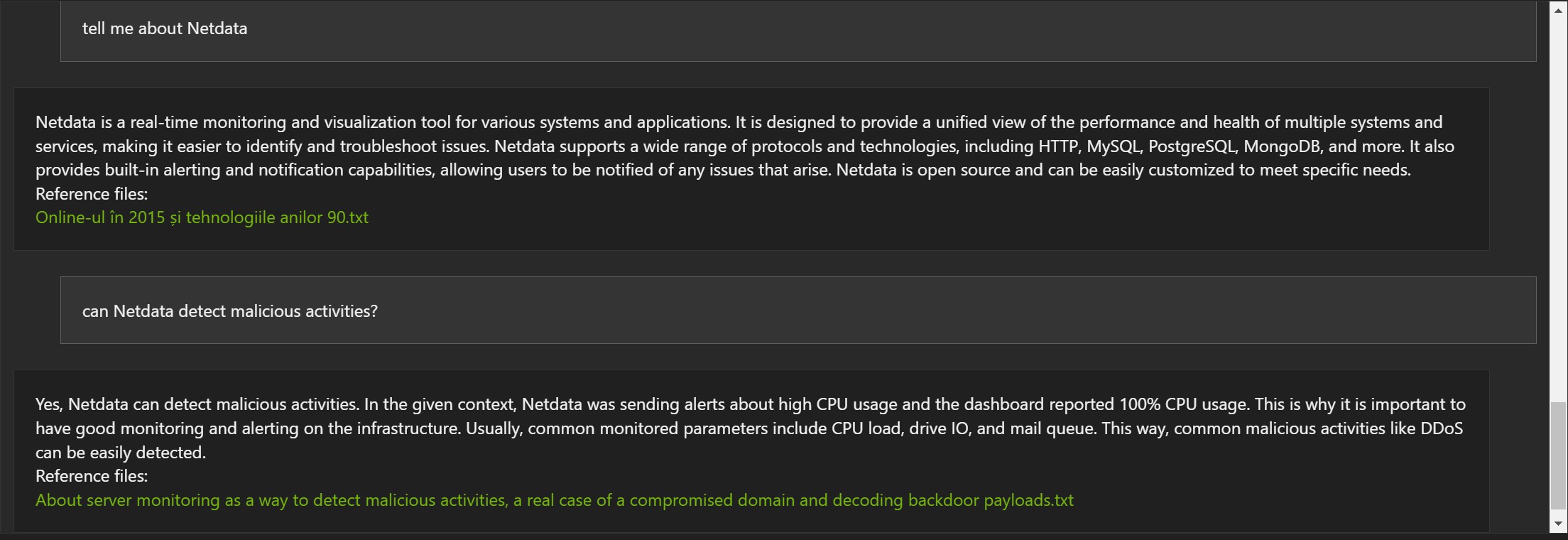
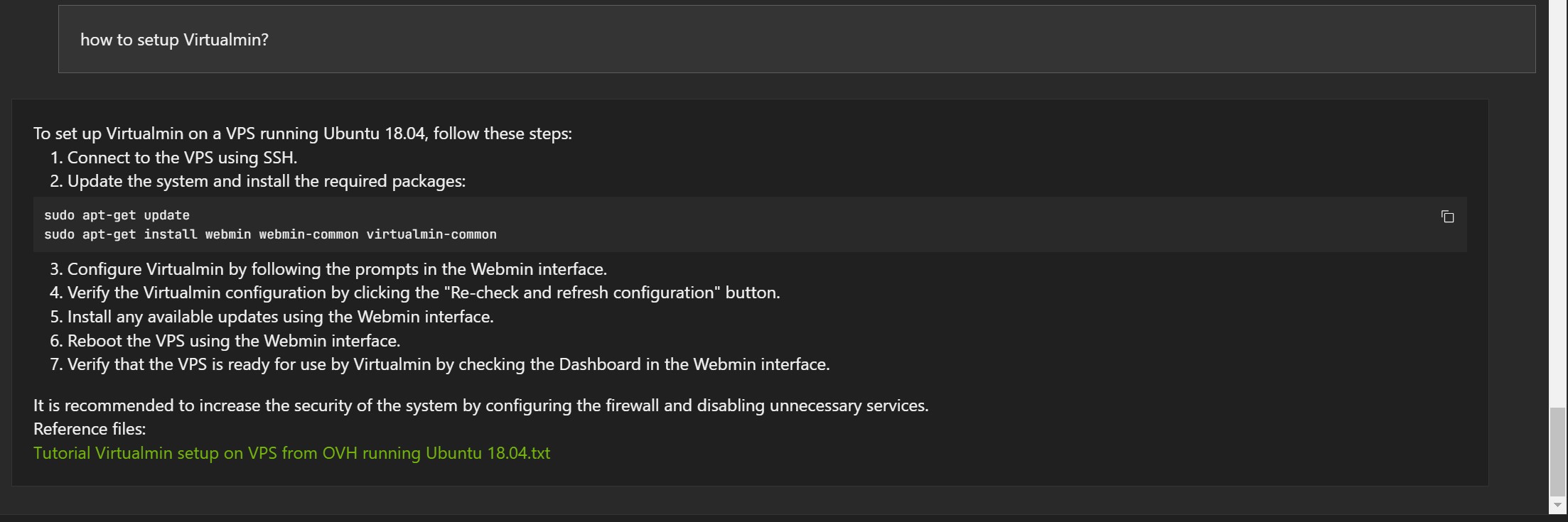
Mai jos vor fi câteva exemple bazate pe articole de pe blog, în limba engleză, și indexate de Chat With RTX:
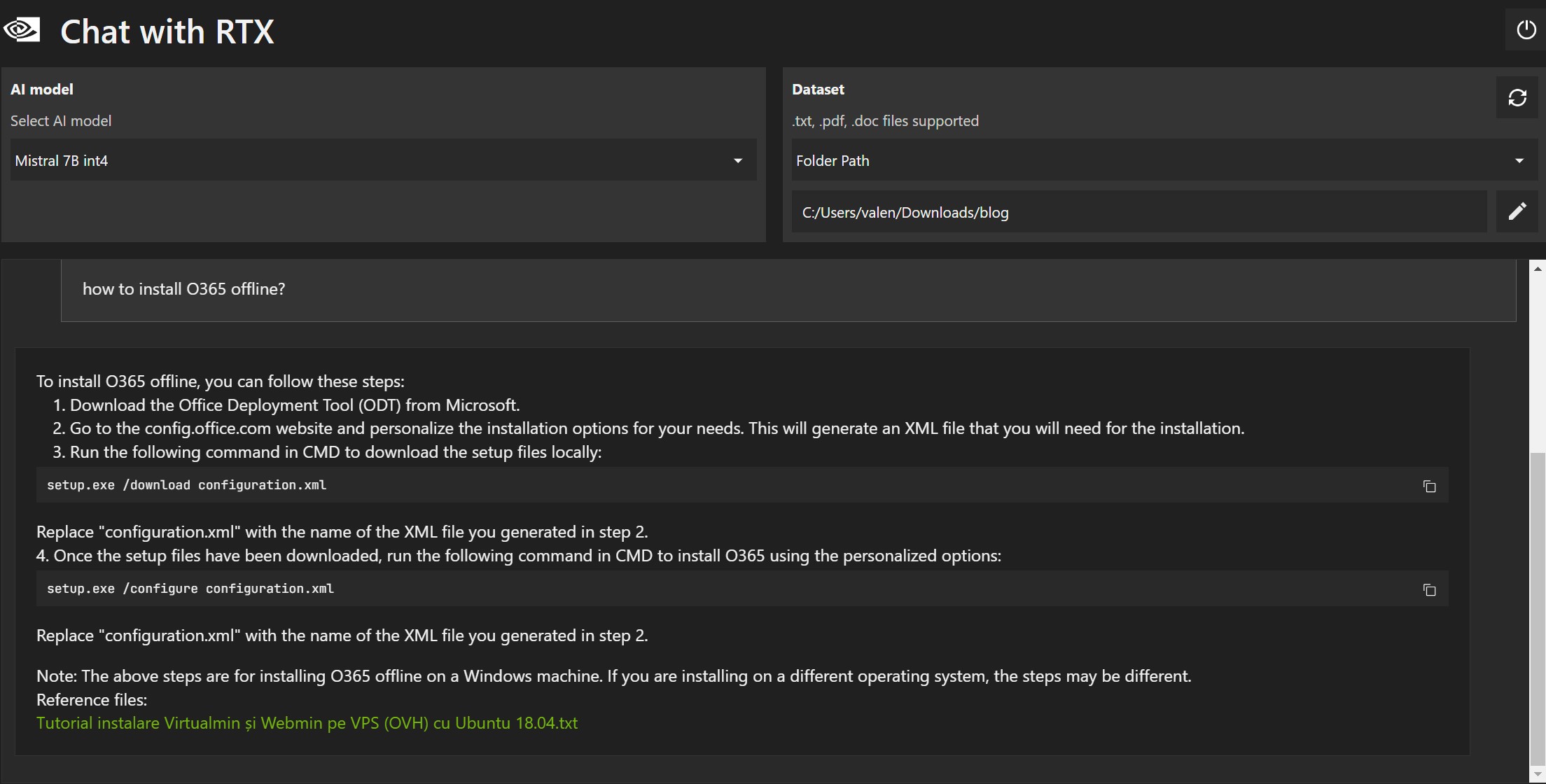
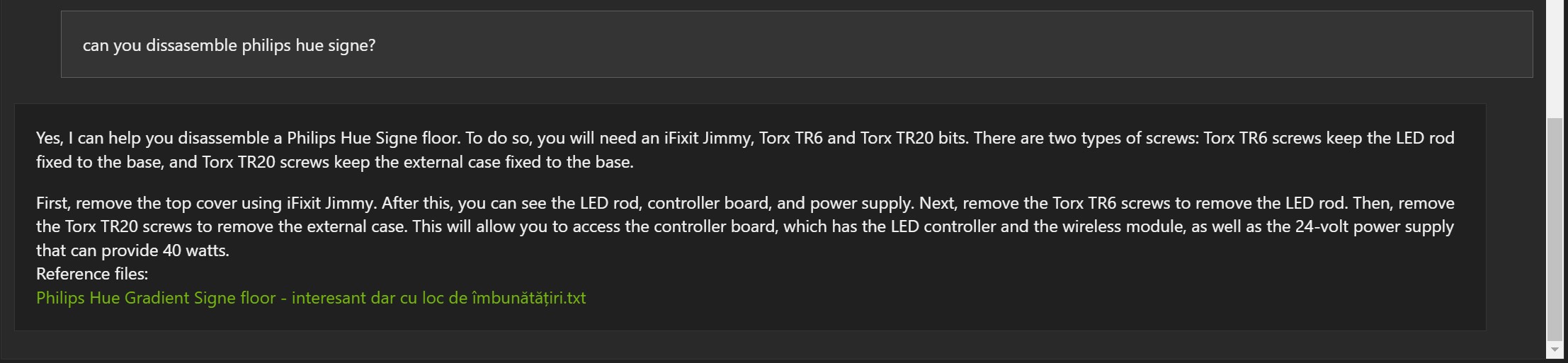

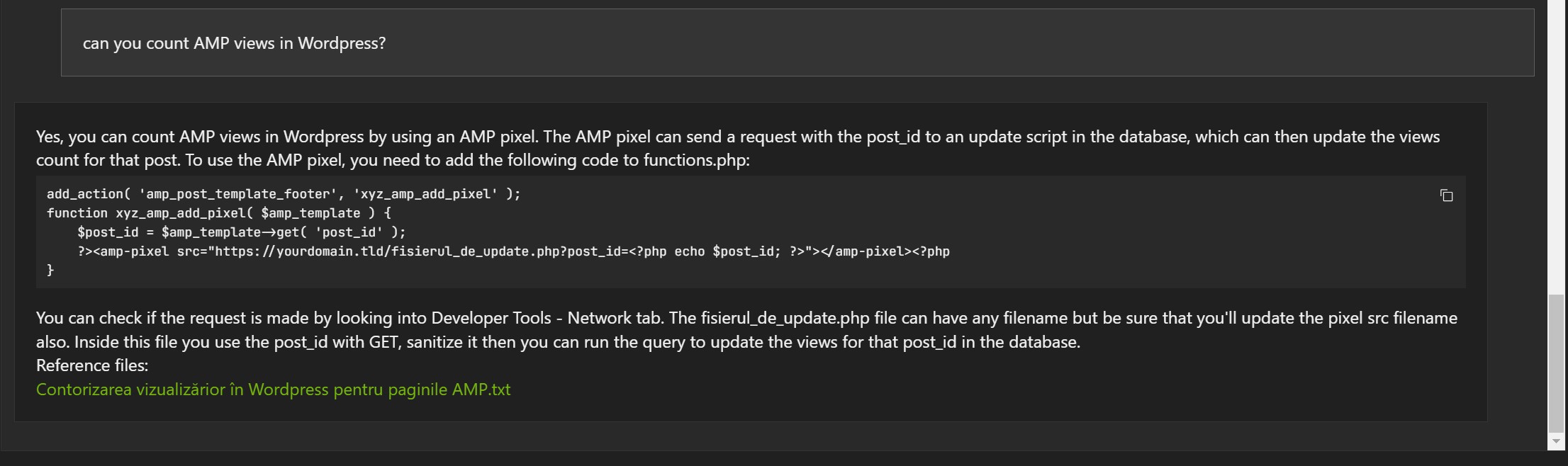
Exemple în limba română:
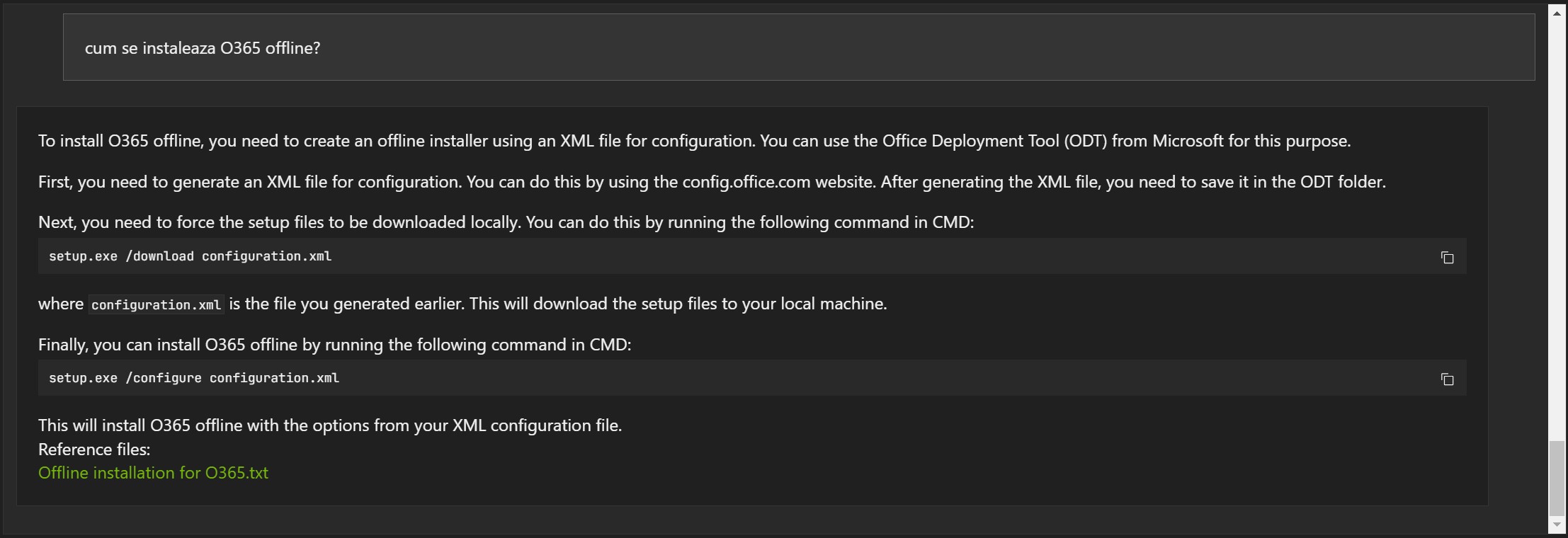
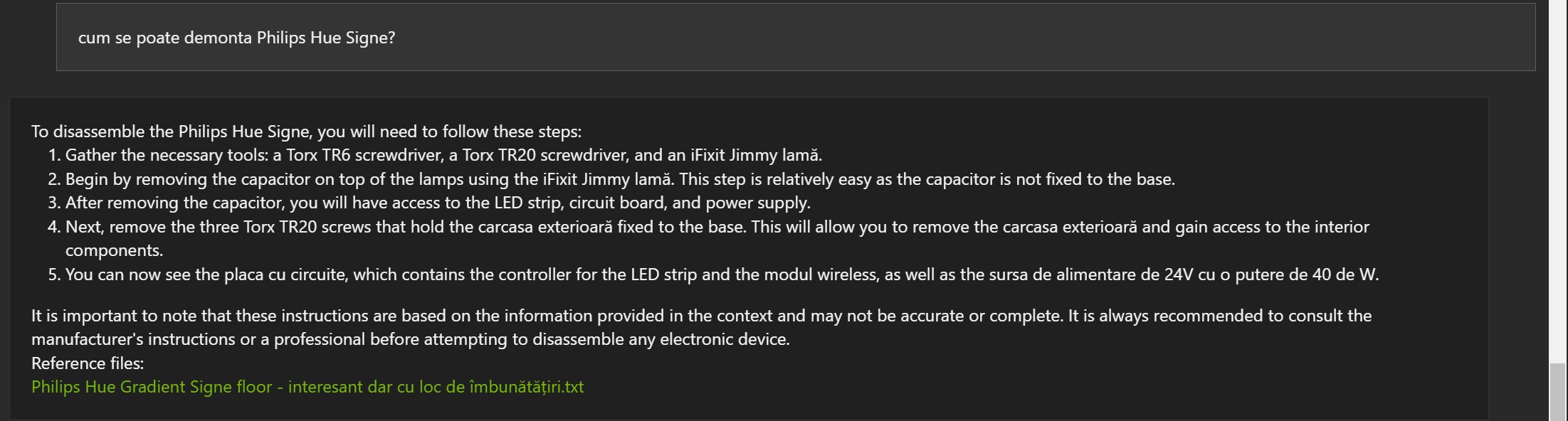

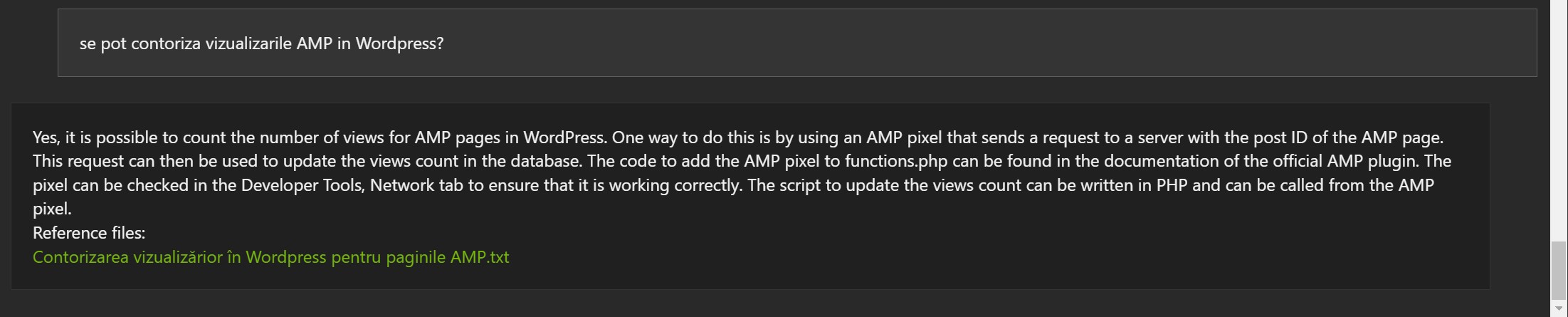
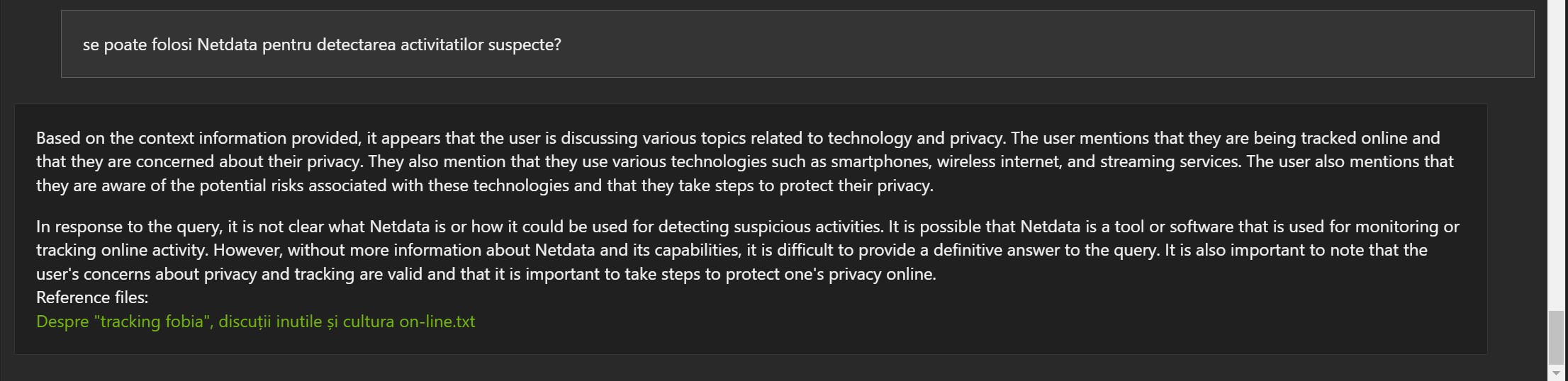
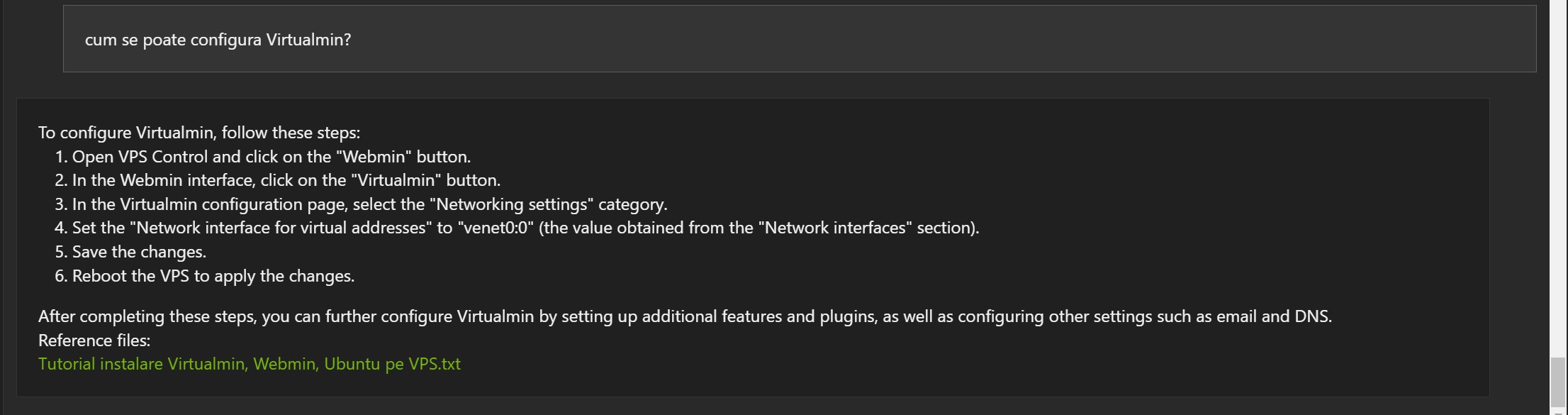
Răspunsurile nu sunt greșite, dar de multe ori documentul referință este greșit (1, 2 și 3).
Primele concluzii:
- Poate fi util și poate înțelege anumite informații
- Modelul Mistral 7B a fost dezvoltat în limba engleză. Acesta poate fi motivul pentru care unele rezultate pot fi ciudate deși aparent modelul a înțeles, măcar parțial informația.
- Cantitatea de informații pentru “aliniament” a fost foarte mică dacă o raportăm la cantitatea de date folosită pentru pre-training.
Ce urmează?
Am câteva teorii. Mă întreb dacă furnizând mai multe date pentru “aliniament” se poate îmbunătăți răspunsul. Voi face niște teste folosind aceleași articole, dar pentru fiecare articol voi genera alte 2-3-4 copii folosind aceeași informație aranjată altfel. Voi reveni cu comparația.